import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 定义LeNet-5模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 卷积层部分
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2) # 输入通道1,输出通道6
self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # 输入通道6,输出通道16
# 全连接层部分
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 16*5*5 -> 120
self.fc2 = nn.Linear(120, 84) # 120 -> 84
self.fc3 = nn.Linear(84, 10) # 84 -> 10 (输出类别)
def forward(self, x):
# 第一层:卷积 -> ReLU -> 平均池化
x = F.relu(self.conv1(x))
x = F.avg_pool2d(x, kernel_size=2, stride=2)
# 第二层:卷积 -> ReLU -> 平均池化
x = F.relu(self.conv2(x))
x = F.avg_pool2d(x, kernel_size=2, stride=2)
# 展平特征图
x = x.view(-1, 16 * 5 * 5)
# 全连接层
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])
# 加载数据集
train_dataset = datasets.MNIST(root='./python_mnist', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./python_mnist', train=False, download=True, transform=transform)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 初始化模型、损失函数和优化器
model = LeNet5().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练函数
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} '
f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
accuracy = 100. * correct / total
avg_loss = train_loss / len(train_loader)
return avg_loss, accuracy
# 测试函数
def test(model, device, test_loader, criterion):
model.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
test_loss /= len(test_loader)
accuracy = 100. * correct / total
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{total} ({accuracy:.2f}%)\n')
return test_loss, accuracy
# 训练过程
epochs = 10
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
print("开始训练LeNet-5...")
for epoch in range(1, epochs + 1):
train_loss, train_acc = train(model, device, train_loader, optimizer, criterion, epoch)
test_loss, test_acc = test(model, device, test_loader, criterion)
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
print("训练完成!")
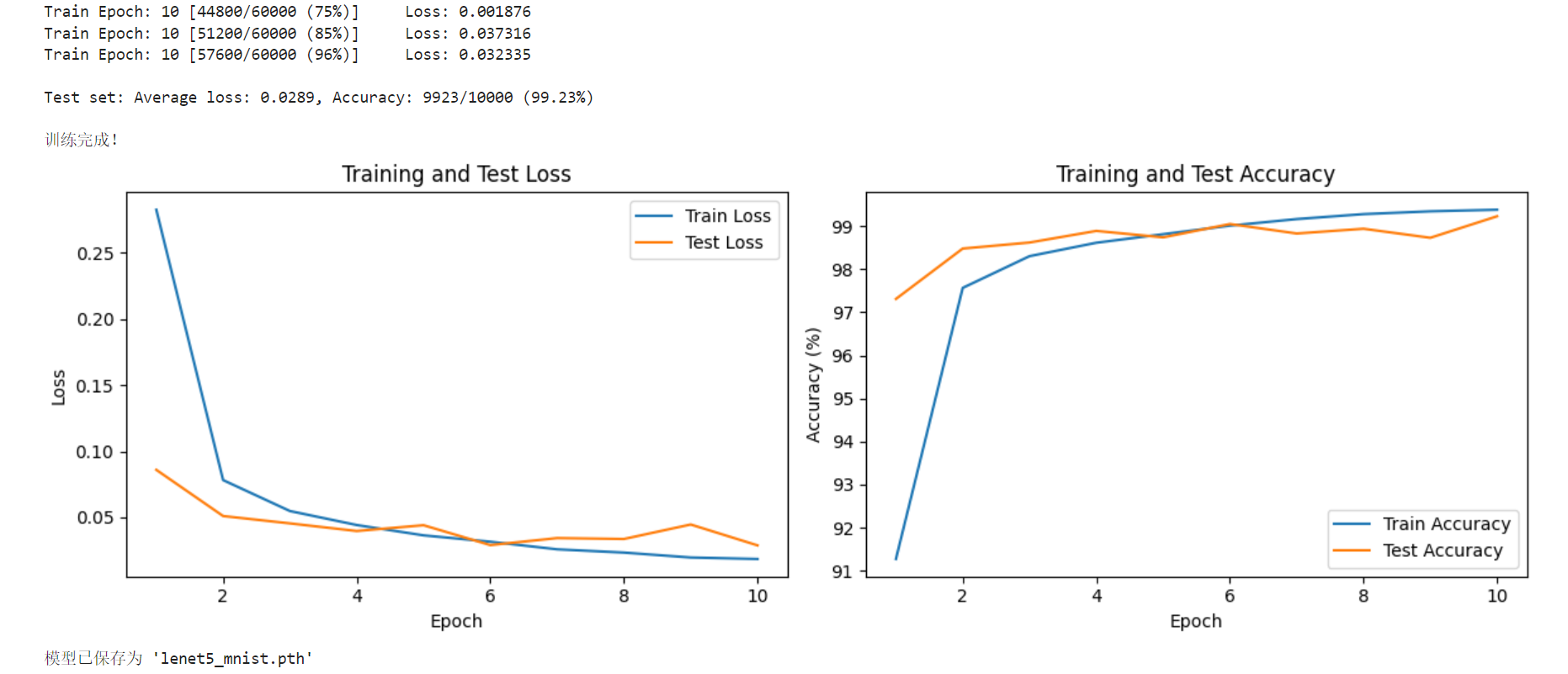
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), train_losses, label='Train Loss')
plt.plot(range(1, epochs + 1), test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Test Loss')
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs + 1), train_accuracies, label='Train Accuracy')
plt.plot(range(1, epochs + 1), test_accuracies, label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.title('Training and Test Accuracy')
plt.tight_layout()
plt.show()
# 保存模型
torch.save(model.state_dict(), 'lenet5_mnist.pth')
print("模型已保存为 'lenet5_mnist.pth'")
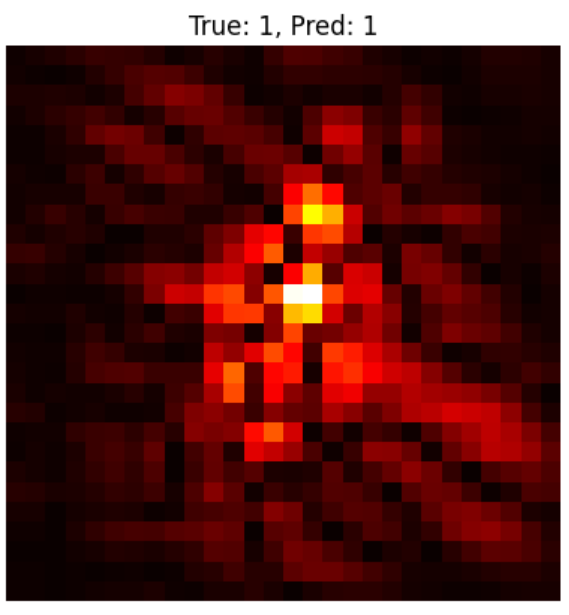
# 在单个图像上测试模型
def predict_single_image(model, device, test_dataset):
model.eval()
# 随机选择一个测试图像
idx = torch.randint(0, len(test_dataset), (1,)).item()
image, label = test_dataset[idx]
# 添加batch维度并预测
image = image.unsqueeze(0).to(device)
with torch.no_grad():
output = model(image)
prediction = output.argmax(dim=1).item()
# 显示图像和预测结果
plt.imshow(image.cpu().squeeze(), cmap='gray')
plt.title(f'True: {label}, Predicted: {prediction}')
plt.axis('off')
plt.show()
return label, prediction
# 测试单个图像
true_label, pred_label = predict_single_image(model, device, test_dataset)
print(f'真实标签: {true_label}, 预测标签: {pred_label}')